Métodos de aprendizaje no supervisado en social listening
2022-09-28import nltk
nltk.data.path.append("/tmp")
nltk.download("stopwords", download_dir="/tmp")
from nltk.corpus import stopwords
import string
import pandas as pdimport re
def clean_text(text):
'''Delete emojis from text
input: text to edit
output: text without emojis'''
regrex_pattern = re.compile(pattern = "["
u"\U0001F600-\U0001F64F" # emoticons
u"\U0001F300-\U0001F5FF" # symbols & pictographs
u"\U0001F680-\U0001F6FF" # transport & map symbols
u"\U0001F1E0-\U0001F1FF" # flags (iOS)
u"\U00002500-\U00002BEF" # chinese char
u"\U00002702-\U000027B0"
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
u"\U0001f926-\U0001f937"
u"\U00010000-\U0010ffff"
u"\u2640-\u2642"
u"\u2600-\u2B55"
u"\u200d"
u"\u23cf"
u"\u23e9"
u"\u231a"
u"\ufe0f" # dingbats
u"\u3030"
"]+", flags = re.UNICODE)
text = regrex_pattern.sub(r'', text)
#remover_puntuacion
translator = str.maketrans('', '', string.punctuation)
text = text.translate(translator)
# Se observan las palabras comunes contenidas en esta librería
spanish_sw = stopwords.words('spanish')
text = [word.lower() for word in text.split() if word.lower() not in spanish_sw]
text = " ".join(text)
text = re.sub('^rt ','',text)
text = re.sub('\d','',text)
return textdf_twi = pd.read_csv('s3://social-listening-otm/Datos-Feria-Flores/feria_flores_twiter.csv',header = 0)
df_twi.head()twi_fecha_creacion twi_hora_creacion twi_id twi_texto twi_georeferenciacion twi_coordenadas twi_lugar twi_cantidadretweet twi_idioma twi_hashtag twi_valoracion
0 2022-08-18 08:33:15 1560258526320427008 RT @AlcaldiadeMed: 🐶🌷Este será uno de los mejo... NaN NaN NaN 10 es FeriaDeLasFlores2022 5
1 2022-08-18 07:03:51 1560236025972236288 RT @Veronicalcocerg: Medellín, felicidades por... NaN NaN NaN 750 es FeriaDeLasFlores2022 5
2 2022-08-18 05:55:06 1560218724380155904 RT @Veronicalcocerg: Un detalle que amo de las... NaN NaN NaN 1076 es FeriaDeLasFlores2022 5
3 2022-08-18 07:16:19 1560239166247649280 RT @Joshua_Arte: Mis #Héroes así no le guste a... NaN NaN NaN 136 es MedellínAquíTodoFlorece 5
4 2022-08-18 07:11:21 1560237914788970496 RT @PabloOrellanaSm: Anoche martes de feria ju... NaN NaN NaN 5 es FeriaDeLasFlores2022 5df_inst = pd.read_csv('s3://social-listening-otm/Datos-Feria-Flores/ferias_flores_instagram.csv',header = 0)
df_inst.head()ins_fecha_creacion ins_hora_creacion ins_id ins_texto ins_cantidad_megusta ins_cantidad_comentarios ins_publicacion ins_hashtag ins_valoracion
0 2022-08-18 00:04:12 17955401299974994 También disfruté la edición once de Fondas de ... 12.0 0 https://www.instagram.com/p/ChY3CovOq3A/ FeriaDeLasFlores2022 5
1 2022-08-18 01:15:05 17931429044396800 "Nunca se pierde el esfuerzo que ponemos para ... 4.0 1 https://www.instagram.com/p/ChY_Jz6uAOe/ FeriaDeLasFlores2022 5
2 2022-08-18 00:21:39 17946022706162429 Cree en ti mism@ eres más valiente de lo que p... 4.0 1 https://www.instagram.com/p/ChY5CV8s9fN/ FeriaDeLasFlores2022 5
3 2022-08-18 00:13:51 17963312560870050 ZONA AZUL DE LA FERIA ANIMARTE. \nEn esta secc... 12.0 0 https://www.instagram.com/p/ChY4JRnsPPa/ FeriaDeLasFlores2022 3
4 2022-08-18 05:30:03 17987559625553412 #valledeaburra #medellincolombia #colombia🇨🇴 #... 1.0 0 https://www.instagram.com/p/ChZcVJ6O2Ht/ FeriaDeLasFlores2022 3df1 = df_twi[['twi_fecha_creacion','twi_texto','twi_hashtag',]]
df1.columns=['fecha','text','hashtag']df2 = df_inst[['ins_fecha_creacion','ins_texto','ins_hashtag']]
df2.columns=['fecha','text','hashtag']df = pd.concat([df1,df2])df['clean_text'] = df.text.apply(clean_text)
df.head()fecha text hashtag clean_text
0 2022-08-18 RT @AlcaldiadeMed: 🐶🌷Este será uno de los mejo... FeriaDeLasFlores2022 alcaldiademed mejores fines semana disfrutar a...
1 2022-08-18 RT @Veronicalcocerg: Medellín, felicidades por... FeriaDeLasFlores2022 veronicalcocerg medellín felicidades culminar ...
2 2022-08-18 RT @Veronicalcocerg: Un detalle que amo de las... FeriaDeLasFlores2022 veronicalcocerg detalle amo silletas siempre t...
3 2022-08-18 RT @Joshua_Arte: Mis #Héroes así no le guste a... MedellínAquíTodoFlorece joshuaarte héroes así guste terrorista mejores...
4 2022-08-18 RT @PabloOrellanaSm: Anoche martes de feria ju... FeriaDeLasFlores2022 pabloorellanasm anoche martes feria junto adan...df.shapedf.clean_text.sample(10)704 último experiencia maravillosa acompañar sille...
324 feria ritmo bicicleta feriaaritmodebicicleta f...
1195 anonymus quinterocalle alcaldiademed fila larg...
724 ¡volvimos florecer silleteros dieron dejaron ...
472 abadcolorado ¿se imaginan q deben familiares l...
553 alcaldiademed medellín siempre ojos mundo sema...
1768 angelfenix hoy sabado así nadita arriba abajo ...
167 slpherreraejc recordemos héroes feriadelasflor...
2221 celebra feriadelasflores feriadelasflores mari...
1396 kit feriadelasflores medellin añosdesfilandoyd...
Name: clean_text, dtype: objectfrom sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizersplit_text2 = content.split()
coun2 = Counter(split_text2)
most_occur2 = coun2.most_common(70) # 70 palabras más comunes
print(most_occur2)list_text = df.clean_text.to_list()
list_text = "..".join(list_text)
print(list_text)# Palabras más frecuentes del texto ordenadas en frecuencia de mayor a menor
# ignorando las palabras que son consideradas poco relevantes,
# De aquí se extraen varios análisis y se pueden ignorar algunas manualmente.
# Se puede mejorar para automatizar más esta elección de palabras más importantes
from collections import Counter
split_text2 = list_text.split()
coun2 = Counter(split_text2)
most_occur2 = coun2.most_common(2000) # 70 palabras más comunes
print(most_occur2)df_ = pd.DataFrame()
df_ = df_.append(most_occur2)
df_.columns = ['Palabra','Frecuencia']df_.head() Palabra Frecuencia
0 feriadelasflores 6250
1 flores 2442
2 feria 2073
3 medellín 1721
4 agosto 1287df_.to_csv('top_palabras_Feria_flores.csv',index=False)Tablero de visualización

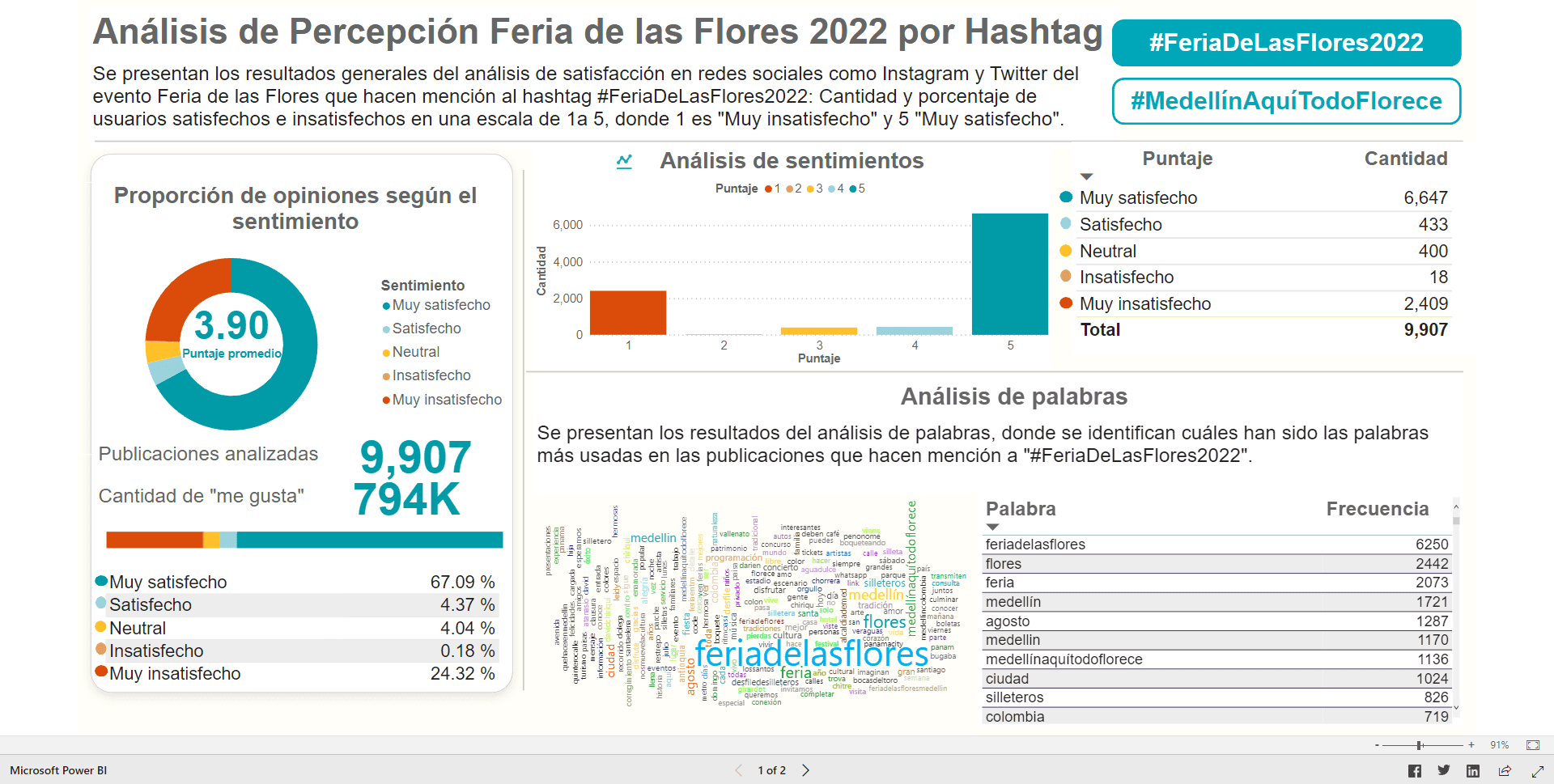
Artículos relacionados
Loading...