Machine Learning Alojamiento (Ruta N)
2022-09-28Descarga los datos para realizar el ejercicio
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.decomposition import TruncatedSVD
from sklearn.cluster import KMeans, MeanShift, DBSCANCarga de datos de alojamiento
file_name = "alojamiento_online_cat_612942d18b.csv"
df = pd.read_csv(file_name, delimiter = ';')Prcesamiento de los datos
# Quitar valores nulos
df_ = df.dropna()# Eliminar variables poco relevantes o redundantes
df_ = df_.drop(['hot_comuna','hot_explica_categoria','hot_nombre','hot_correo','hot_direccion','hot_longitud','hot_latitud'],axis=1)
df_.drop([425],axis=0,inplace=True)
df_.shape# Muestra de los datos de alojamiento
df_.sample(50) hot__id hot_habitaciones hot_camas hot_num_emp hot_puntuacion hot_posicionranking hot_codigopostal hot_zona hot_categoria
638 8782588 130.0 2000.0 30.0 4.5 220 500300.0 Laureles-Estadio 4
935 11741998 410.0 5600.0 100.0 4.5 228 500300.0 Laureles-Estadio 2
847 656344 760.0 15400.0 500.0 4.5 89 500220.0 El Poblado 1
516 20104017 70.0 700.0 20.0 5.0 408 500220.0 El Poblado 4
334 3195011 110.0 1100.0 30.0 4.5 223 500220.0 El Poblado 4
927 4183392 40.0 1400.0 30.0 2.5 900 500210.0 El Poblado 4
528 9979275 420.0 4200.0 60.0 2.5 145 500160.0 Centro 2
699 10090391 800.0 12500.0 280.0 4.5 54 500310.0 Laureles-Estadio 1
568 15123107 160.0 2000.0 140.0 2.0 224 500210.0 El Poblado 3
752 9462527 30.0 300.0 10.0 5.0 245 500170.0 Santa Elena 4
949 11910208 100.0 5000.0 30.0 5.0 166 500210.0 El Poblado 4
729 3334644 100.0 1200.0 30.0 4.0 919 500210.0 El Poblado 4
878 10326757 120.0 1200.0 30.0 5.0 912 500210.0 El Poblado 4
588 2521106 300.0 3800.0 120.0 3.5 287 500310.0 Laureles-Estadio 2
399 11717554 50.0 2800.0 40.0 4.0 662 500310.0 Laureles-Estadio 4
503 7306366 470.0 6600.0 290.0 4.0 171 500210.0 El Poblado 2
726 17607831 50.0 2500.0 10.0 1.0 349 500120.0 Centro 4
964 10185492 110.0 1900.0 30.0 4.5 109 500340.0 Laureles-Estadio 4
749 2259621 200.0 4000.0 40.0 4.5 196 500070.0 Santa Elena 4
841 1116522 1340.0 16200.0 450.0 4.5 79 500210.0 El Poblado 1
940 1986176 420.0 5200.0 370.0 4.0 496 500210.0 El Poblado 2
397 7198899 130.0 4400.0 50.0 4.5 14 500210.0 El Poblado 4
328 1747746 1080.0 26600.0 740.0 4.0 438 500120.0 Centro 1
589 4954520 140.0 2200.0 40.0 4.0 229 500210.0 El Poblado 4
913 12500421 880.0 35700.0 300.0 4.0 177 500210.0 El Poblado 1
759 676819 390.0 8700.0 270.0 4.5 185 500220.0 El Poblado 2
633 307377 840.0 12700.0 1000.0 4.5 150 500220.0 El Poblado 1
772 14013969 700.0 7000.0 150.0 4.5 19 500210.0 El Poblado 1
410 1131516 80.0 2400.0 30.0 4.0 631 500210.0 El Poblado 4
778 10781160 820.0 9800.0 310.0 4.0 951 500210.0 Centro 1
765 8804344 350.0 3700.0 150.0 3.0 951 500210.0 El Poblado 2
394 7159071 180.0 4000.0 20.0 3.5 107 500210.0 El Poblado 3
312 15618472 130.0 1800.0 10.0 4.0 272 500210.0 El Poblado 4
484 4660517 190.0 3100.0 10.0 3.0 308 500300.0 Laureles-Estadio 3
798 23425494 420.0 4900.0 110.0 4.0 494 500210.0 El Poblado 2
429 7168690 730.0 7300.0 120.0 3.0 37 500140.0 Centro 1
539 17383435 310.0 5600.0 160.0 3.5 469 500210.0 El Poblado 2
647 2677821 220.0 3000.0 30.0 4.0 479 500310.0 Laureles-Estadio 3
409 8682661 210.0 5000.0 20.0 4.5 105 500310.0 Laureles-Estadio 3
571 2266782 260.0 3800.0 80.0 3.5 419 500310.0 Laureles-Estadio 2
629 1197730 980.0 24000.0 110.0 4.0 463 500160.0 Centro 1
520 1453454 1680.0 19100.0 970.0 4.5 501 500220.0 El Poblado 1
581 18344006 350.0 3500.0 20.0 3.0 429 500250.0 Laureles-Estadio 2
716 299105 2940.0 38500.0 1850.0 4.0 35 500210.0 El Poblado 1
48 13839497 100.0 7000.0 30.0 4.5 367 500210.0 El Poblado 4
547 754675 130.0 1300.0 10.0 3.5 655 500220.0 El Poblado 4
466 12712680 100.0 1800.0 20.0 3.5 374 500300.0 Laureles-Estadio 4
632 1499042 160.0 3200.0 80.0 3.5 628 500220.0 El Poblado 3
435 2287871 70.0 1000.0 10.0 4.0 696 500220.0 El Poblado 4
988 1625519 60.0 2100.0 20.0 4.5 805 500320.0 Laureles-Estadio 4# Convertir los valores a numéricos
df_.loc[:,'hot_zona'], _ = pd.factorize(df_.hot_zona)
df_.loc[:,'hot_categoria'] = df_.hot_categoria.astype(int,copy=False)# Dividir del conjunto de datos la variable objetivo y las características
y = df_['hot_categoria']
X = df_.drop(['hot_categoria'],axis=1)# Se normalizan los datos
def mean_norm(df_input):
return df_input.apply(lambda x: (x-x.mean())/ x.std(), axis=0)
X = mean_norm(X)
X.head()hot__id hot_habitaciones hot_camas hot_num_emp hot_puntuacion hot_posicionranking hot_latitud hot_longitud hot_codigopostal hot_zona
8 1.139591 -0.472094 -0.603672 -0.414992 1.262718 -0.525368 0.658776 0.502166 -0.271792 -0.702118
12 1.247206 -0.650224 -0.637800 -0.414992 1.262718 -0.844135 0.661032 0.502171 -0.449110 -0.702118
24 0.673888 -0.491886 -0.569544 -0.452606 0.604378 -0.119320 0.660688 0.502170 -0.449110 -0.702118
28 2.137597 -0.195002 -0.421657 -0.302148 1.262718 -0.248345 0.038582 0.507314 1.324076 0.342496
48 0.935819 -0.571055 0.010630 -0.452606 0.604378 0.267754 0.658570 -1.910820 -0.449110 -0.702118# Unimos datos normalizados con variable objetivo "hot_categoria"
df_2 = pd.concat([X, y],axis=1)
df_2.head(10)hot__id hot_habitaciones hot_camas hot_num_emp hot_puntuacion hot_posicionranking hot_codigopostal hot_zona hot_categoria
8 1.139591 -0.472094 -0.603672 -0.414992 1.262718 -0.525368 -0.271792 -0.702118 4
12 1.247206 -0.650224 -0.637800 -0.414992 1.262718 -0.844135 -0.449110 -0.702118 4
24 0.673888 -0.491886 -0.569544 -0.452606 0.604378 -0.119320 -0.449110 -0.702118 4
28 2.137597 -0.195002 -0.421657 -0.302148 1.262718 -0.248345 1.324076 0.342496 2
48 0.935819 -0.571055 0.010630 -0.452606 0.604378 0.267754 -0.449110 -0.702118 4
52 -0.931482 -0.531471 -0.376153 -0.264534 -0.712302 1.455541 1.856032 0.342496 4
56 -1.144178 -0.313756 -0.205513 0.149224 -0.053962 -0.263524 -0.449110 -0.702118 3
86 -0.977003 -0.610640 -0.307897 -0.490220 -0.053962 -0.202806 -0.449110 -0.702118 4
90 0.547326 -0.571055 -0.410281 -0.527835 -0.712302 2.286612 -0.271792 -0.702118 4
101 -0.733698 -0.412717 -0.501289 -0.339763 -0.712302 -0.077577 -0.271792 -0.702118 3Reducción Dimensión
#Análisis de componentes principales PCA
pca = PCA(n_components=2, random_state = 1)
df_c_pca = pca.fit_transform(X)
df_visual = pd.DataFrame(df_c_pca)
df_visual['y'] = y.values
plt.figure(figsize = (12, 8))
sns.scatterplot(data = df_visual,x = 0, y = 1,hue = 'y', palette = 'Set2',s=150).set(title='PCA')
plt.savefig('pca_hotels.png',bbox_inches='tight')
plt.show()
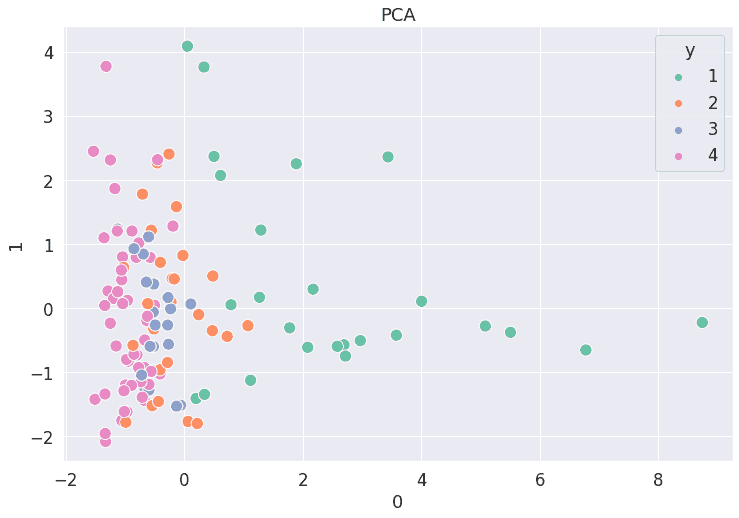
# Reducción dimensionalidad usando truncated SVD (aka LSA).
svd = TruncatedSVD(n_components=2, random_state = 1)
df_svd = svd.fit_transform(df_2)
df_visual = pd.DataFrame(df_svd)
df_visual['y'] = y.values
plt.figure(figsize = (12, 8))
sns.scatterplot(data = df_visual, x = 0, y = 1, hue = 'y', palette = 'Set2',s=150).set(title='Truncated SVD')
plt.savefig('truncated_svd_hotels.png',bbox_inches='tight')
plt.show()
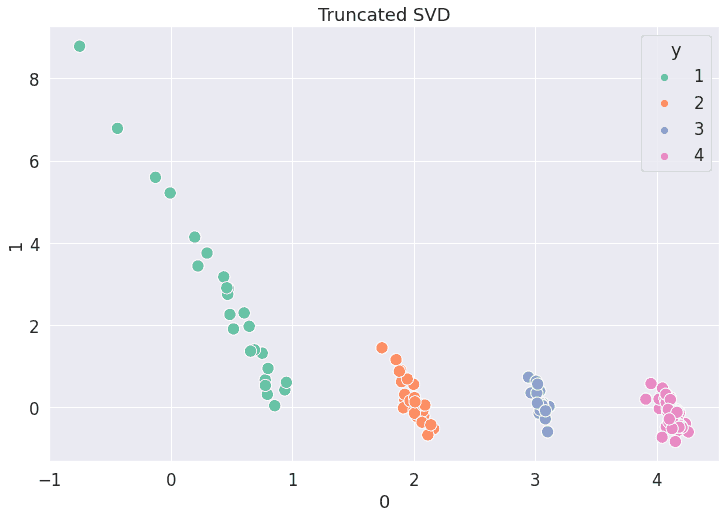
# Reducción dimensionalidad usando manifold TSNE
X_embedded = TSNE(n_components=2, learning_rate='auto',
init='random', perplexity=3).fit_transform(df_2)
df_visual = pd.DataFrame(X_embedded)
df_visual['y'] = y.values
# sns.set(font_scale=2)
plt.figure(figsize = (12, 8))
sns.scatterplot(data = df_visual, x = 0, y = 1, hue = 'y', palette = 'Set2',s=150).set(title='Manifold TSNE')
plt.savefig('manifold_TSNE_hotels.png',bbox_inches='tight')
plt.show()

# Reducción dimensionalidad usando manifold Isomap
embedding = Isomap(n_components=2)
X_transformed = embedding.fit_transform(df_2)
df_visual = pd.DataFrame(X_transformed)
df_visual['y'] = y.values
sns.set(font_scale=1.5)
plt.figure(figsize = (12, 8))
sns.scatterplot(data = df_visual, x = 0, y = 1, hue = 'y', palette = 'Set2',s=150).set(title='Manifold Isomap')
plt.savefig('manifold_isomap_hotels.png',bbox_inches='tight')
plt.show()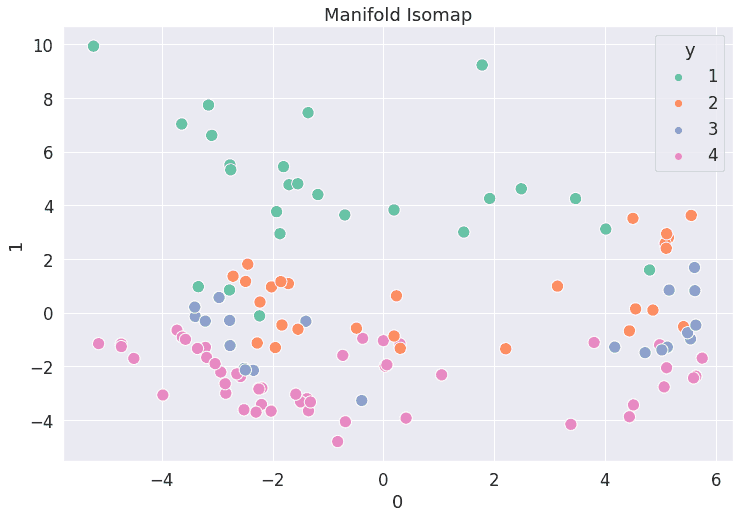
Artículos relacionados
Loading...